Huffman Coder
Hello humans, this week the “AI-DreamTeam” developed a compressor using the Hufmman algorithm and a BFS(Best-First-Search) tree.
This algorithm compresses strings and text files using the character’s frequency. The higher the frequency is, higher the compression level will be.
Now, a demo:
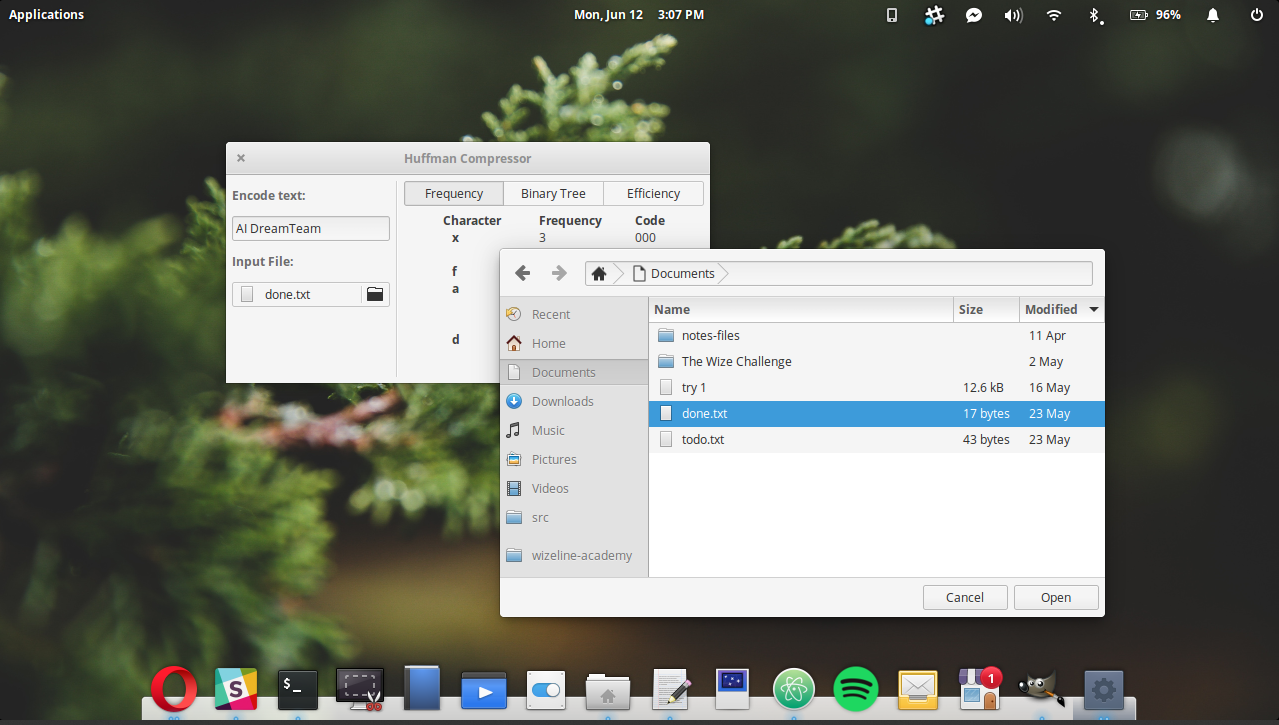
On the left side we can type a string or choose a text file using the “file browser” icon.
On the right side are three buttons:
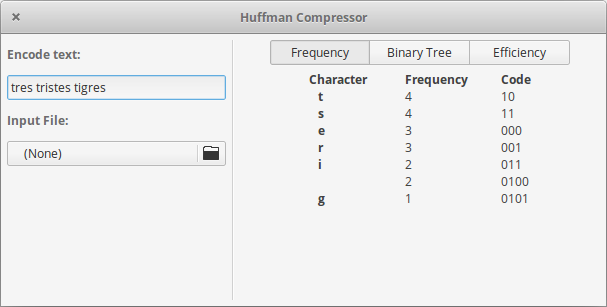
- Frequency: This window will show the frequency table. the table has the character, the frequency of occurrence, and the binary code assigned by the algorithm.
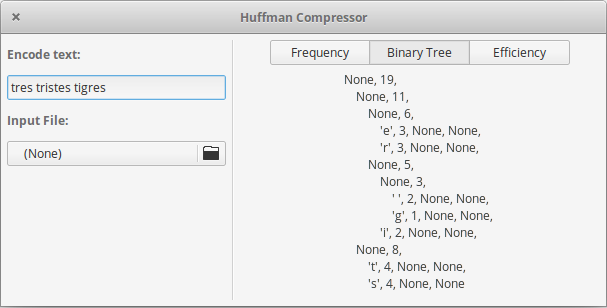
- Binary tree: In this part, you can see a representation of the binary tree.
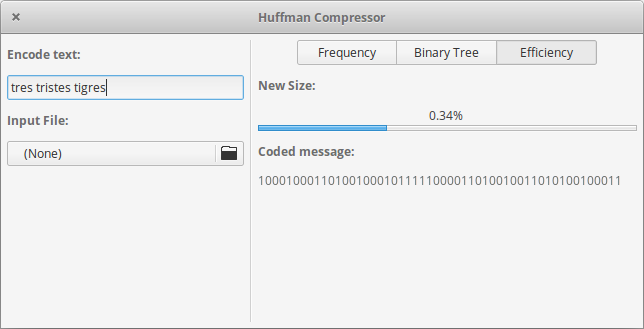
- Efficiency: Here we have the binary representation of the compressed text and the efficiency percentage of the algorithm
The piece of code that traverses the tree and generates the Huffman code for each letter is the following:
#Recursive method which traverses the tree until it finds the Huffman code for
#the [letter] parameter and stores it in [codeArray]
def getCode(letter, currentNode, isCodeFound, codeArray):
if currentNode[0] == letter:
isCodeFound = True
return isCodeFound
elif Huffman.hasLeaves(currentNode):
if Huffman.hasLeftNode(currentNode):
codeArray.append('0')
isCodeFound = Huffman.getCode(letter, Huffman.getLeftNode(currentNode), isCodeFound, codeArray)
if Huffman.hasRightNode(currentNode) and not isCodeFound:
codeArray.append('1')
isCodeFound = Huffman.getCode(letter, Huffman.getRightNode(currentNode), isCodeFound, codeArray)
if not isCodeFound:
if len(codeArray) > 0:
codeArray.pop()
return isCodeFound